
ik分词器解析
ElasticSearch中iK分词器的两种分词算法以及自定义分词配置
分词:就是把我们要查询的数据拆分成一个个关键字,我们在搜索时,ElasticSearch会把数据进行分词,然后做匹配。默认的中文分词器会把每一个中文拆分,比如“番茄呦呦”,会拆分成“番”,“茄”,“哟”,“哟”,显然,这并不符合我们的要求,所以ik分词器(中文分词器)能解决这个问题。
ik分词器存在两种分词算法:
ik_smart,ik_max_word。其中ik_smart称为智能分词,网上还有别的称呼:最少切分,最粗粒度划分。ik_max_word称为最细粒度划分。
当然我们也可以自定义分词配置
安装好ik分词器后,启动ElasticSearch以及kibana。使用kibana测试
ik_smart测试
1 | GET _analyze |

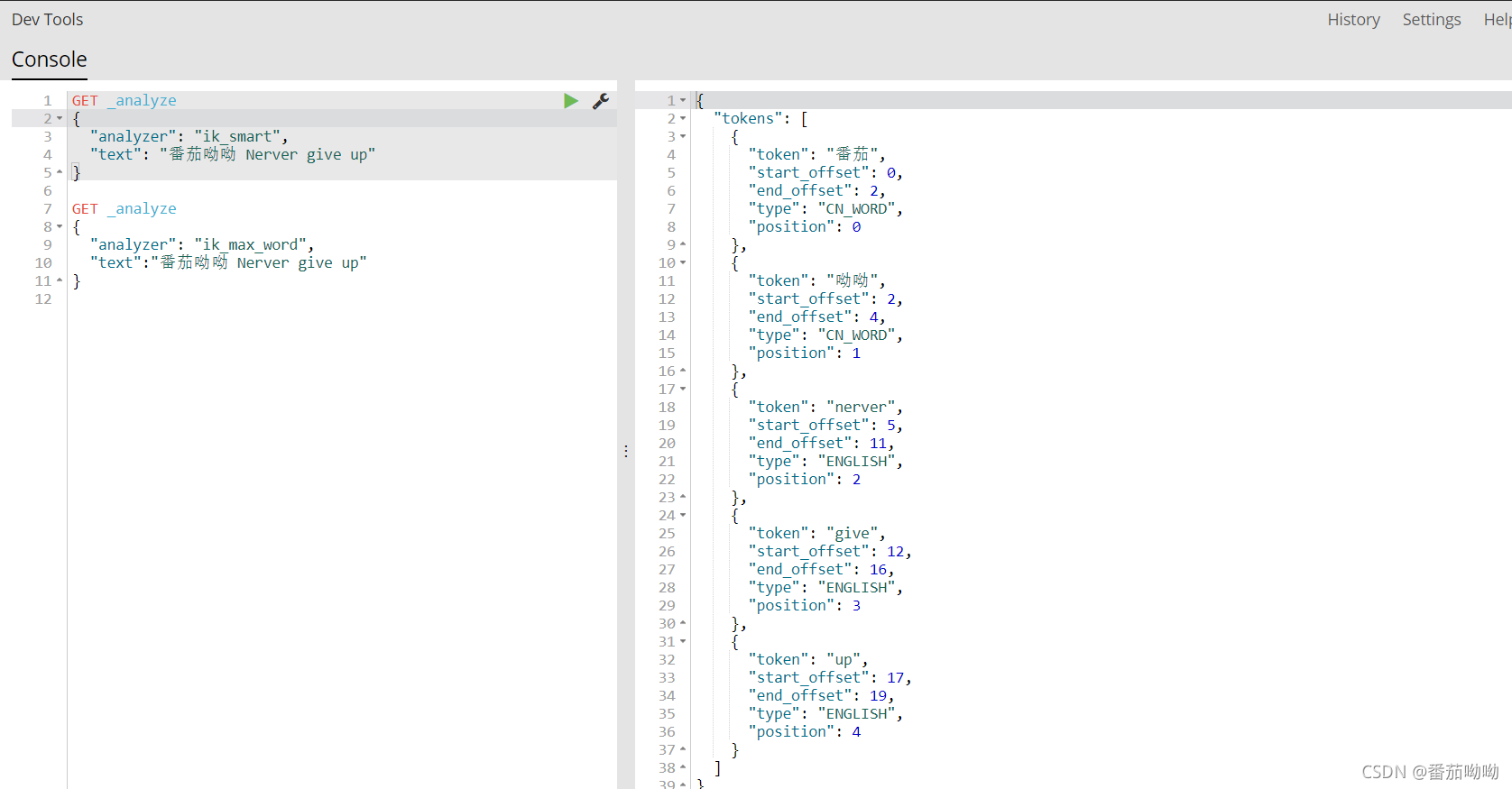
我们发现ik_smart将数据拆分成了5份
ik_max_word测试
1 | GET _analyze |
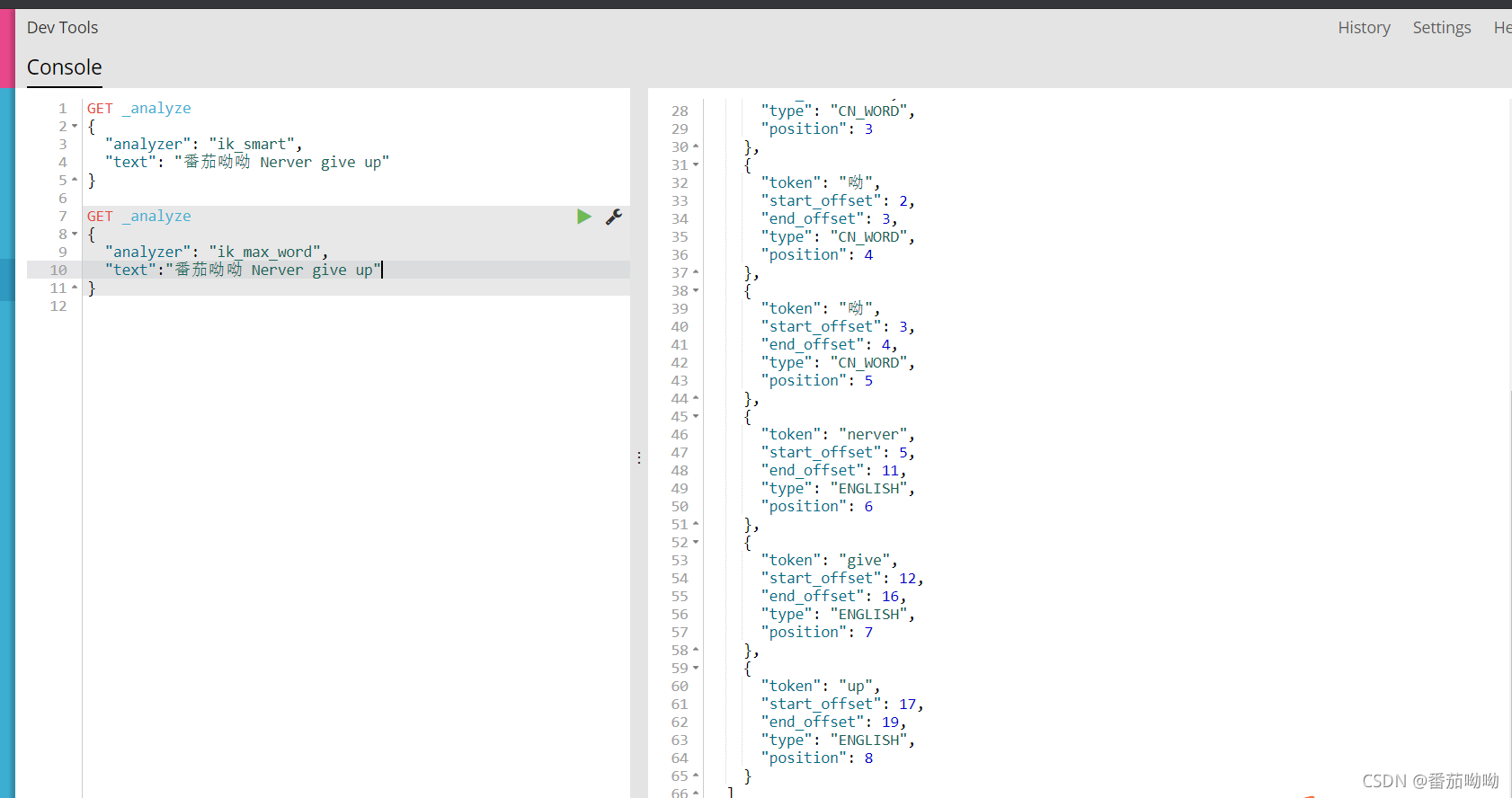
我们发现ik_smart将数据拆分成了9份,他会穷尽所有字典中的可能
两种分词算法的对比
确实在ik分词器中,ik_smart和ik_max_word的分词有明显区别
但是上方案列中,如果我们不想把“番茄呦呦”拆分,我们想把“番茄呦呦”作为其中一个词来进行匹配.
自定义分词配置
找到ElasticSearch的安装目录下的plugin目录,下面有ik分词器的相关配置,
找到config目录,打开IKAnalyzer.cfg.xml文件
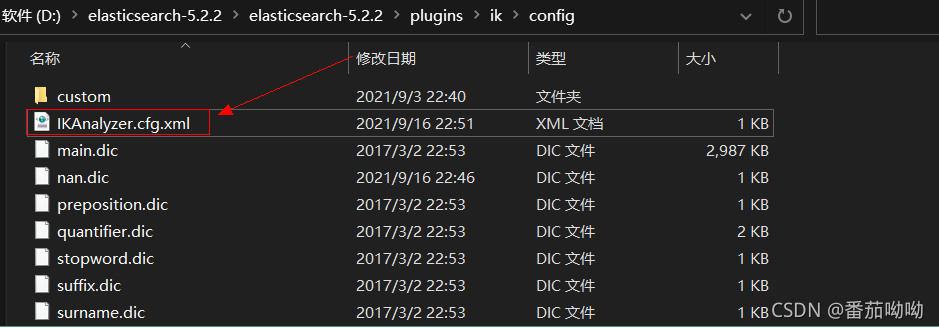
可以自定义分词配置
多个分词配置用分号隔开
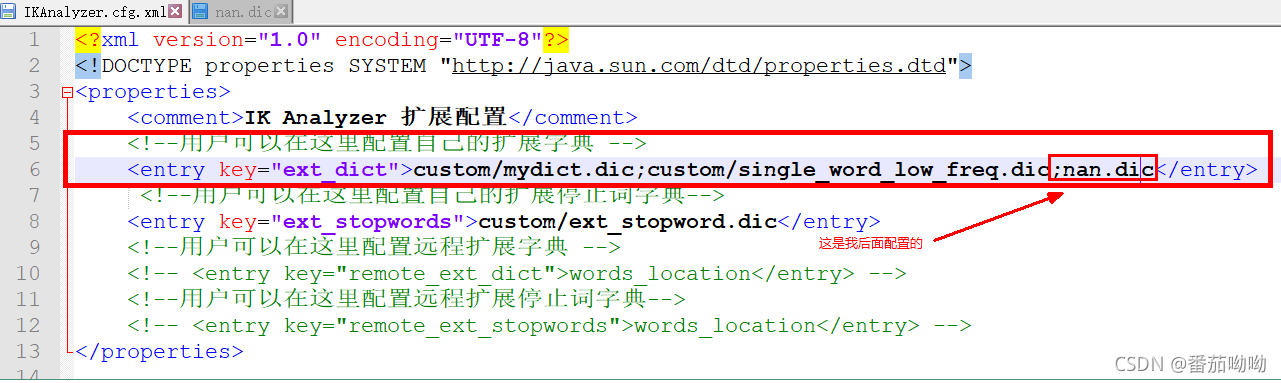 我在配置文件中加了一个 ;nan.dic(注意:多个分词配置用分号隔开)
我在配置文件中加了一个 ;nan.dic(注意:多个分词配置用分号隔开)
现在还要自己写一个nan.dic字典
在IKAnalyzer.cfg.xml文件同级目录下创建一个nan.dic
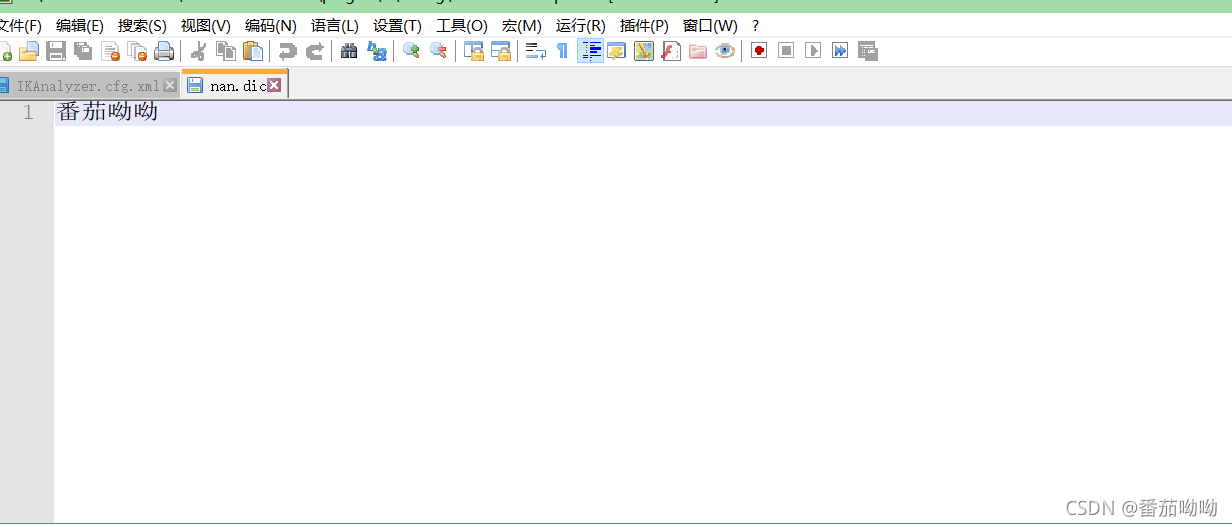
里面加上你不想要拆分的词,保存之后,重启es
自定义分词配置测试
再次运行之前的语句
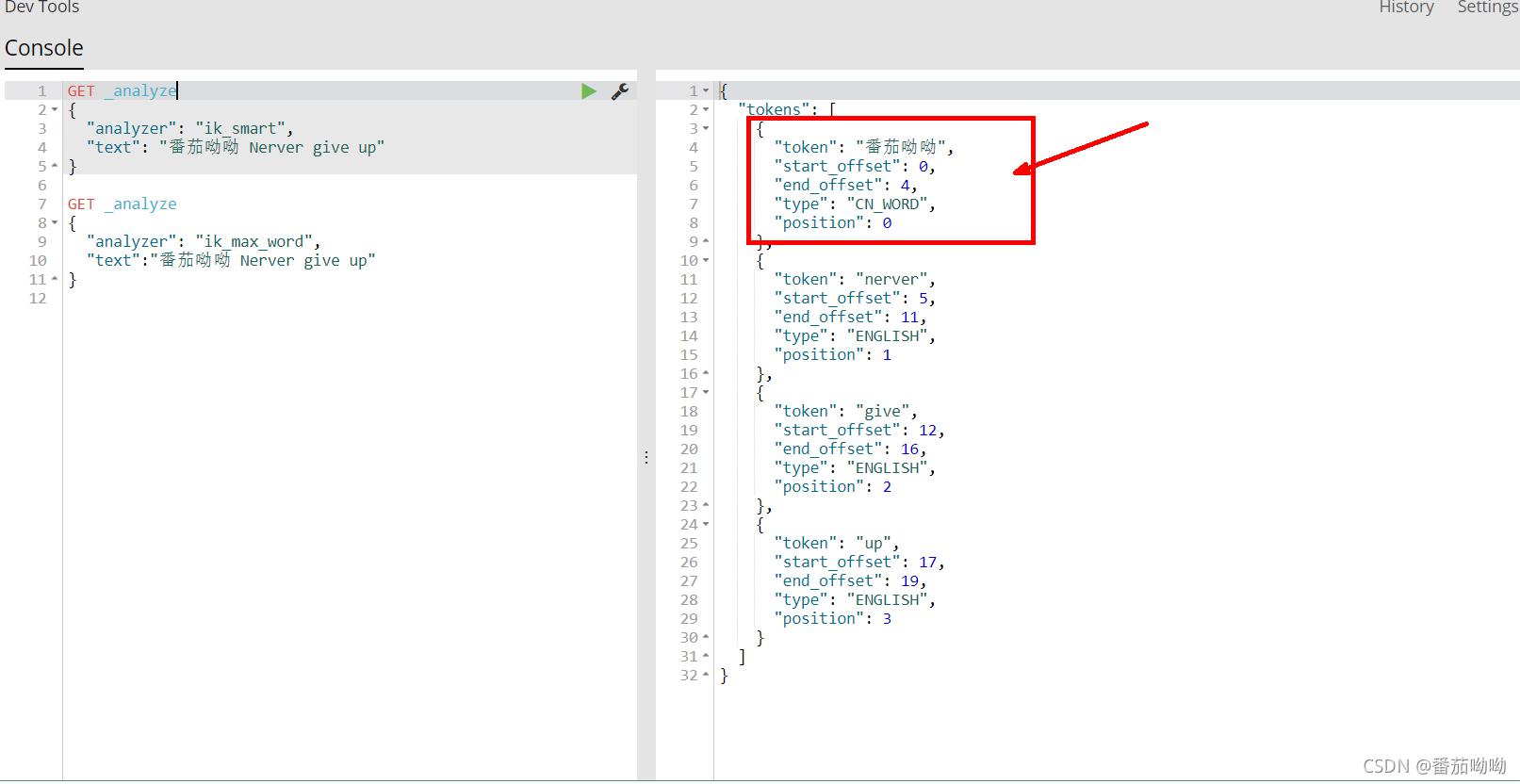
我们发现ik_smart没有拆分“番茄呦呦”,成功,nice。
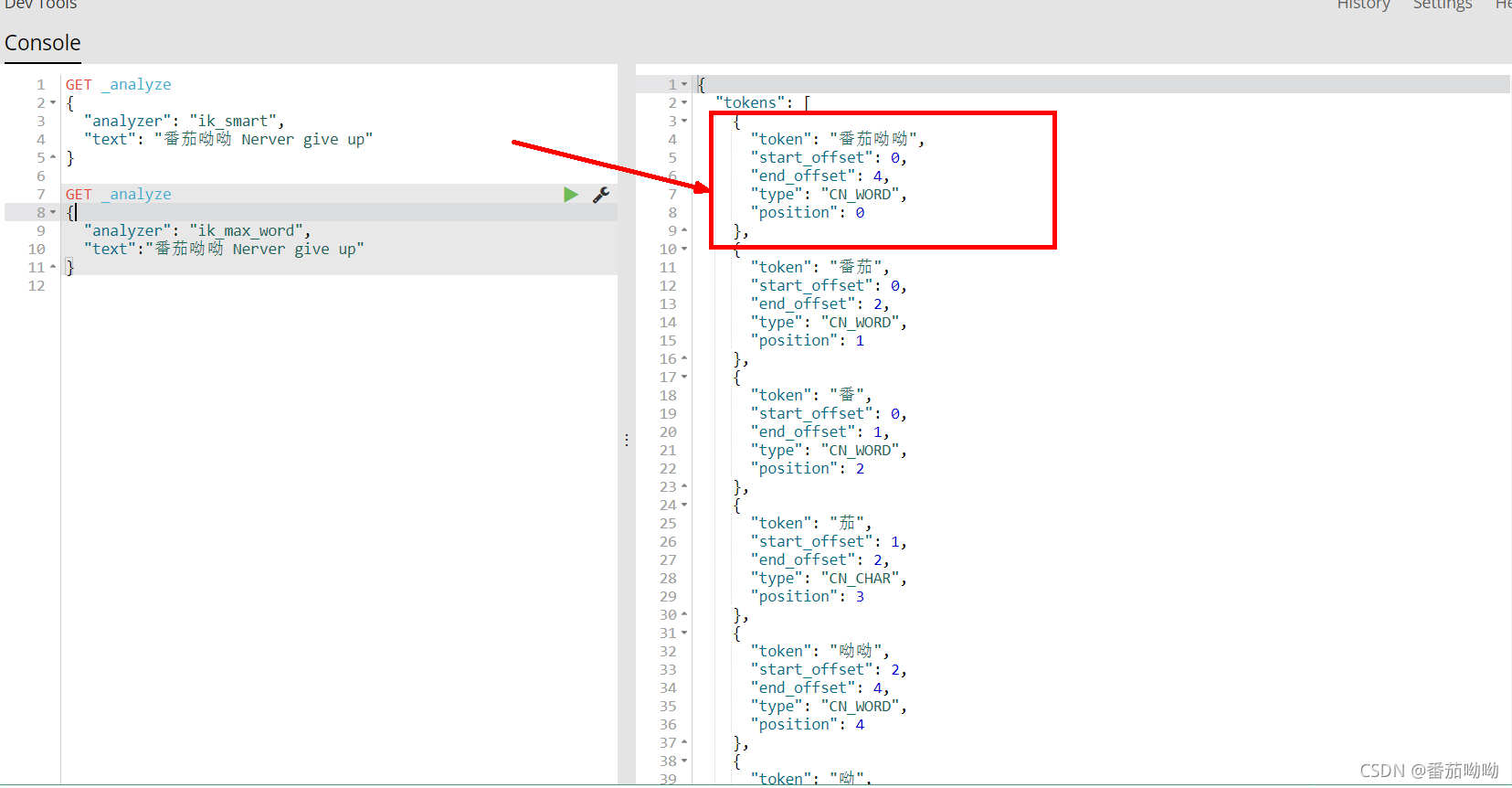
ik_max_word虽然拆分了“番茄呦呦”,但是也将“番茄呦呦”作为了其中一个关键字匹配
成功,nice
观看狂神说视频所记录
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 NBlog!